DubWise: Video-Guided Speech Duration Control in Multimodal LLM-based Text-to-Speech for Dubbing
Model Architecture
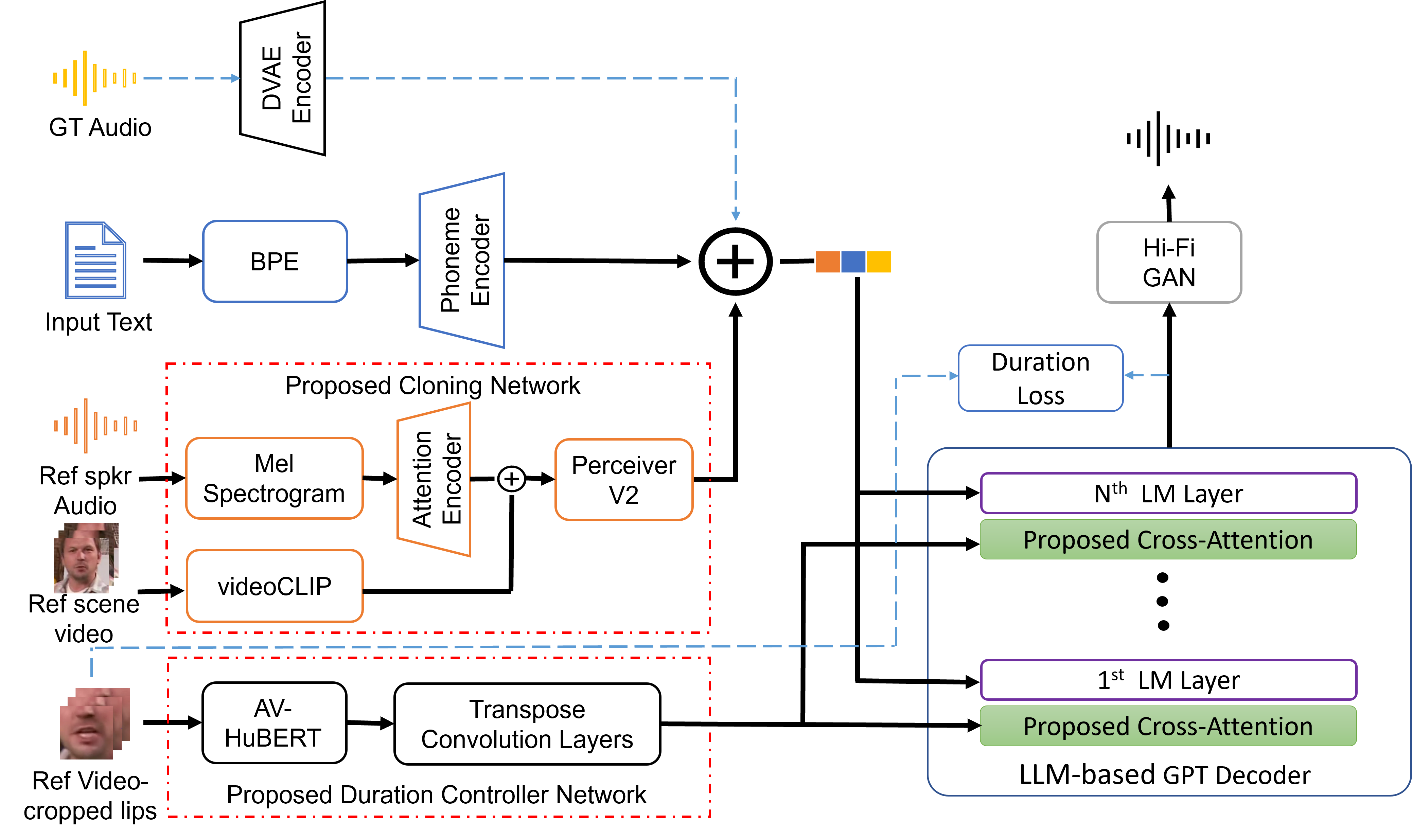
Proposed Method: Tokenized reference-speaker audio and text form the model's prompt (ground truth audio included during training only). Lip region video is fed through cross-attention. HiFi-GAN generates speech from the output.
Cross-Lingual TTS Examples
Example 1: Input Text: यह अभिक्रिया निर्देशांक अभिक्रिया प्रगति हैं, जो कुछ सेकंड या एक शून्य वर्षो मैं जा सक्ति हैं।
Input English Reference Video
Proposed DubWise
XTTS+WSOLA
YourTTS
Example 2: Input Text: समय के एक कार्य के रूप में एकाग्रता अधिक तेजी से बढ़ रही है, और पहले के समय में संतुलन प्राप्त कर रही है।
Input English Reference Video
Proposed DubWise
XTTS+WSOLA
YourTTS
Example 3: Input Text: अब एक परमाणु, जैसा की आप जानते हैं, सबसे छोटा कण हैं जो किसी तत्व के गुणों को बरकरार रखता है
Input English Reference Video
Proposed DubWise
XTTS+WSOLA
YourTTS
Example 4: Input Text: तो फिर नाभिक में और क्या है?
Input English Reference Video
Proposed DubWise
XTTS+WSOLA
YourTTS
Non-Paralle TTS Examples
Example 1: Input Text: So if you know few bond energies, you can calculate the entropy for lot of reactions.
Input English Reference Video
Proposed DubWise
XTTS+WSOLA
YourTTS
Fastspeech2
HPMDub
Example 2: Input Text: So you can just, instead of looking at 10 to the minus 10 you can say what's the.
Input English Reference Video
Proposed DubWise
XTTS+WSOLA
YourTTS
Fastspeech2
HPMDub
Example 3: Input Text: So I can measure current flow in Ams in an electronic cell that forces galvanic cell.